1. Druid에 Load
Data를 가져와서(Extract) 가공(Transform)한 후 Druid에 올린다(Load). [전형적인 ETL]
드루이드에 올릴 때는 json으로 input source 및 dataSchema에 대한 정보를 적어주고 api로 전송한다.
curl -X 'POST' -H 'Content-Type:application/json' -d @{spec에관한JSON경로[Datasource에 관한 내용도 포함되어 있음]} http://{druid주소}/druid/indexer/v1/task
2. Airflow 자동화
Airflow는 Metadata와 설정된 DAG들을 참고하여 Scheduler가 Worker에 일을 시키는 구조를 지닌 워크플로우 관리 플랫폼이다.

일반적으로 파이썬을 통해 ETL을 자동화 구성한다면,
DAG를 설정하는 소스를 Scheduler에 등록하고 Worker에 소스를 Deploy해서 쓴다. 1
3. 전체적인 자동화 ETL 구조
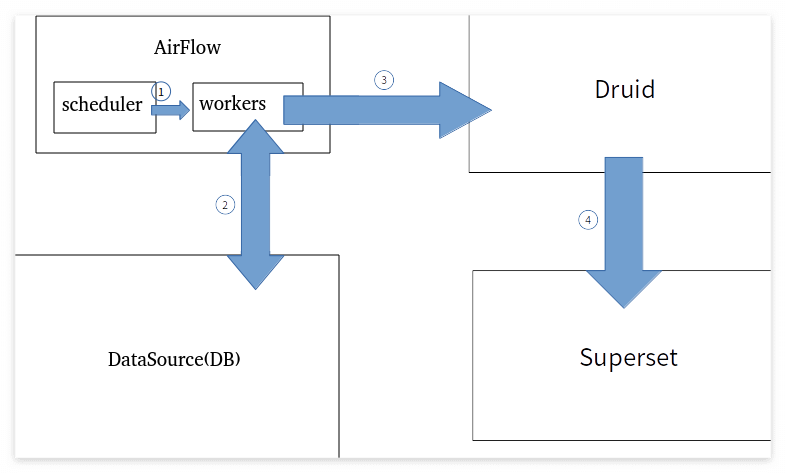
1) scheduler가 cron으로 정해진 시간대에 worker한테 정해진 DAG를 실행시킨다.
2) worker는 Datasource에 가서 쿼리를 날리거나 수집하는 형태로 정해진 데이터를 받는다
3) worker에서 가공하여 Druid로 보낸다.
4) Druid는 Superset에 연계되어 데이터 시각화 및 통계를 제공한다.
- Worker와 Scheduler 및 Metadata DB는 각자 분리해 구성하는 것이 합리적으로 보인다. Worker들을 여러 대 관리해야 Airflow의 효율이 더 좋기 때문이다. 또한 한 Device로 scheduler에 Worker까지 구성하면 시스템이 확장될수록 scheduler의 기능적 제약이 있을 수도 있다. [본문으로]
'ETL 관련' 카테고리의 다른 글
| [생각정리] load balancer가 있는 상황에서 output 처리 (0) | 2023.09.13 |
|---|---|
| df dropna와 NaN replace[groupby시 유의점] (0) | 2023.07.04 |
| 데이터 병합 시 유의해야 할 data type 문제 (0) | 2023.07.03 |
| Druid에 insert와 delete 하는 방식 (0) | 2023.02.15 |
| [Data] Druid와 Superset (0) | 2023.01.09 |