디버깅 모드는 지정된 포인트 혹은 에러에 도달했을 때, 멈춰서 변수들이나 현재 프로세스의 상태를 보여주는 모드이다.
활용 방식
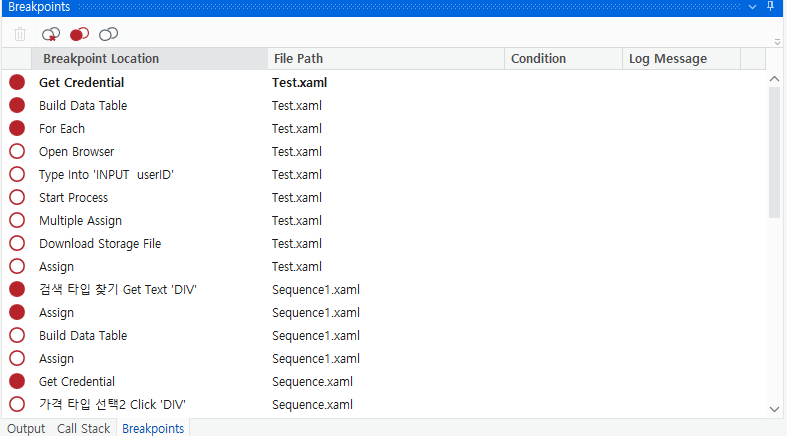
1. Breakpoint
2. Locals
3. Watch
4. Immediate
1. Breakpoint [단축키 F9]
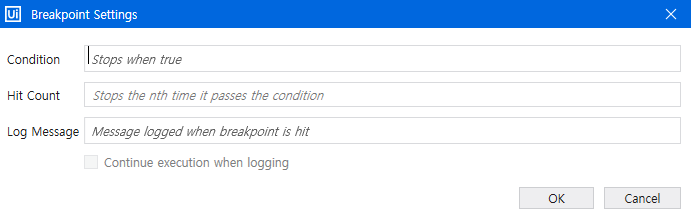
- breakpoint는 잠깐 멈추는 지점을 의미한다. [다른 언어들도 공통되는 개념]
- breakpoint로 지정된 line(또는 activity)은 실행되지 않고 그 직전까지 실행된다.
- breakpoint로 지정하면 빨간색 표시가 뜬다.
- breakpoint로 멈추는 것에 조건을 줄 수도 있다. 그렇게 설정하면 해당 포인트에서 특정 조건이 달성되면 멈춘다.
Conditional Breakpoint
- 해당 지점에서 멈췄을 경우 Log도 따로 지정 가능하다. 이런 기능을 사용하면 로깅을 위해 굳이 if문을 만들어줄 필요가 없다. 특히 output datatable 같은 거 해서 로그 찍어놓고 확인하는 그런 경우가 많은데 굳이 그럴 필요가 없다. [이 setting도 있지만 아래에서 소개하는 기능을 활용하는 게 훨씬 편하다.]
- 스위치는 bulk로 끄고 켤 수도 있다.
위쪽 버튼을 활용하면 한꺼번에 껐다가 한꺼번에 켰다가 할 수도 있다.
2. Locals
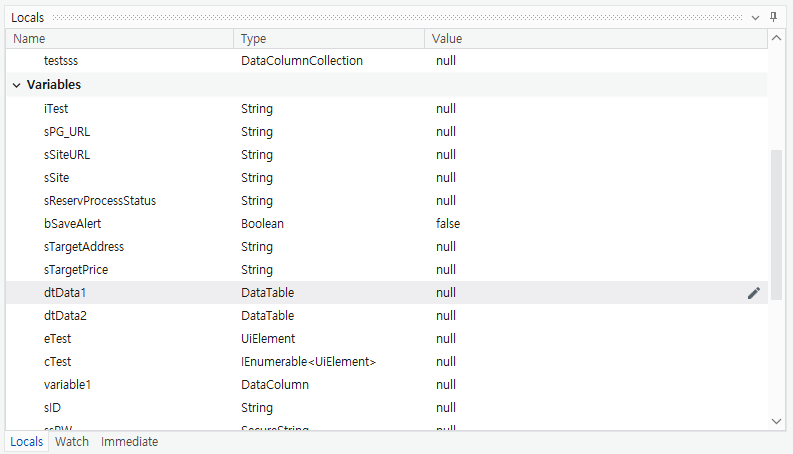
- Locals에는 현재 break된 곳에 있는 모든 변수의 상태값을 보여준다.
- breakpoint와 함께 활용되어 실제 값이 어떻게 들어가는지 간단하게 볼 수 있다.
- 연필모양을 누르면 값을 볼 수 있고, 값을 편집하고 그 상태로 이어서 수행하는 것도 가능하다.
Locals의 예시. break된 scope에서 call할 수 있는 변수가 모두 나온다.
3. Watch
- 변수들의 특정값을 지정해서 추적할 수 있다.
- 가령 Locals에서는 dtContainer의 값을 보여주지만, dtContainer.AsEnumerable.Skip(i_irownum).Take(i_itakenum).CopyToDataTable 같은 값은 보여주지 않는다. 하지만 그런 값을 디버깅할 때 추적해야 한다면 여기에 기입하고 추적하면 된다.
4. Immediate
- 값을 쓰면 즉각적으로 표시된다. 다른 언어로 치면 terminal이나 console창 느낌으로 보면 된다.
- 예를 들어, dtContainer를 쓰면 dtContainer의 내용이 표시된다.
- 추적할 값으로 설정할 필요는 없으나 즉각적으로 어떤 변수의 값을 확인하고 싶은 경우 활용할 수 있다.
- dayofweek같은 걸 추적으로 찍어놨는데 dayofweek의 .ToString('d')값과 .Tostring('g')값이 어떤 차이가 있는지 같은 걸 확인할 때 많이 쓴다.
SQS: Simple Queue Service의 약자. AWS에서 나온 큐 서비스다. 큐를 쏴놓고 소진할 때까지 받으면 되기 때문에 멀티 프로세싱이나 로그 밸런싱 하기가 쉽다. FIFO로 할 건지 무작위로 할 건지 선택할 수 있다. 무작위로 하면 들어온 순서와 무관하게 큐를 준다. 매월 백만개까지는 무료라고 하니 로깅이나 마스터 정보 수준의 크기가 아니라면 가볍게 쓸만한 거 같다. 유료 수준으로 넘어가도 백만개당 0.5불 정도다.
Kafka: 아키텍쳐내에 여러 시스템이 등장하면서 데이터의 복잡성이 커지자 교통정리를 해주고 메시지, 이벤트에 대한 최적화, 로드 밸런싱이 필요해지게 되었다. 그래서 등장한 개념이 이벤트 트리거, 메시지 트리거들이다. 보통 이벤트 트리거들은 메시지를 따로 저장하기 때문에 캐싱이 되고 메시지 트리거 역할도 할 수 있다. 카프카는 이벤트 트리거로서 시스템 간의 데이터 transfer 주체를 producer, consumer로 나누고 내부에 topic - partition을 둠으로써 각 주체가 topic별 트리거링을 할 수 있게 해뒀다. consumer가 메시지를 요청(poll)하면 fetch가 돼있는 경우 fetch된 곳에서 자료를 갖다주며, 아닌 경우 partition에서 레코드를 갖다 준다.